
In this week’s post, Global Graphics Software’s principal engineer, Andrew Cardy, explores the structure tagging API in the Mako™ Core SDK. This feature is particularly valuable as it allows developers to create PDFs that can be read by screen readers, such as Jaws®. This helps blind or partially sighted users unlock the content of a PDF. Here, Andy explains how to use the structure tagging API in Mako to tag both text and images:
What can we Structure Tag?
Before I begin, let’s talk about PDF: PDF is a fixed-format document. This means you can create it once, and it should (aside from font embedding or rendering issues) look identical across machines. This is obviously a great thing for ensuring your document looks great on your user’s devices, but the downside is that some PDF generators can create fixed content that is ordered in a way that is hard for screen readers to understand.
Luckily Mako also has an API for page layout analysis. This API will analyze the structure of the PDF, and using various heuristics and techniques, will group the text on the page together in horizontal runs and vertical columns. It’ll then assign a page reading order.
The structure tagging API makes it easy to take the layout analysis of the page and use it to tag and structure the text. So, while we’re tagging the images, we’ll tag the text too!
Mako’s Structure Tagging API
Mako’s structure tagging API is simple to use. Our architect has done a great job of taking the complicated PDF specification and distilling it down to a number of useful APIs.
Let’s take a look at how we use them to structure a document from start to finish:
Setting the Structure Root
Setting the root structure is straight forward. Firstly, we create an instance of IStructure and set it in the document.
Next we create an instance of a Document level IStructureElement and add that to the structure element we’ve just created.
One thing that I learnt the hard way, is that Acrobat will not allow child structures to be read by a screen reader if their parent has alternative (alt) text set.
Add alternate text only to tags that don’t have child tags. Adding alternate text to a parent tag prevents a screen reader from reading any of that tag’s child tags. (Adobe Acrobat help)
Originally, when I started this research project, I had alt text set at the document level, which caused all sorts of confusion when my text and image alt text wasn’t read!
Using the Layout Analysis API
Now that we’ve structured the document, it’s time to structure the text. Firstly, we want to understand the layout of the page. To do this, we use IPageLayout. We give it a reference to the page we want to analyze, then perform the analysis on it.
Now the page has been analyzed, it’s easy to iterate through the columns and nodes in the page layout data.
Tagging the text
Once we’ve found our text runs, we can tag our text with a span IStructureElement. We append this new structure element to the parent paragraph created while we were iterating over the columns.
We also tag the original source Mako DOM node against the new span element.
Tagging the images
Once the text is structured, we can structure the images too.
Earlier, I used Microsoft’s Vision API to take the images in the document and give us a textual description of them. We can now take this textual description and add it to a figure IStructureElement.
Again, we make sure we tag the new figure structure element against the original source Mako DOM image.
Notifying Readers of the Structure Tags
The last thing we need to do is set some metadata in the document’s assembly, this is straight forward enough. Setting this metadata helps viewers to identify that this document is structure tagged.
Putting it all Together
So, after we’ve automated all of that, we now get a nice structure, which, on the whole, flows well and reads well.
We can see this structure in Acrobat DC:
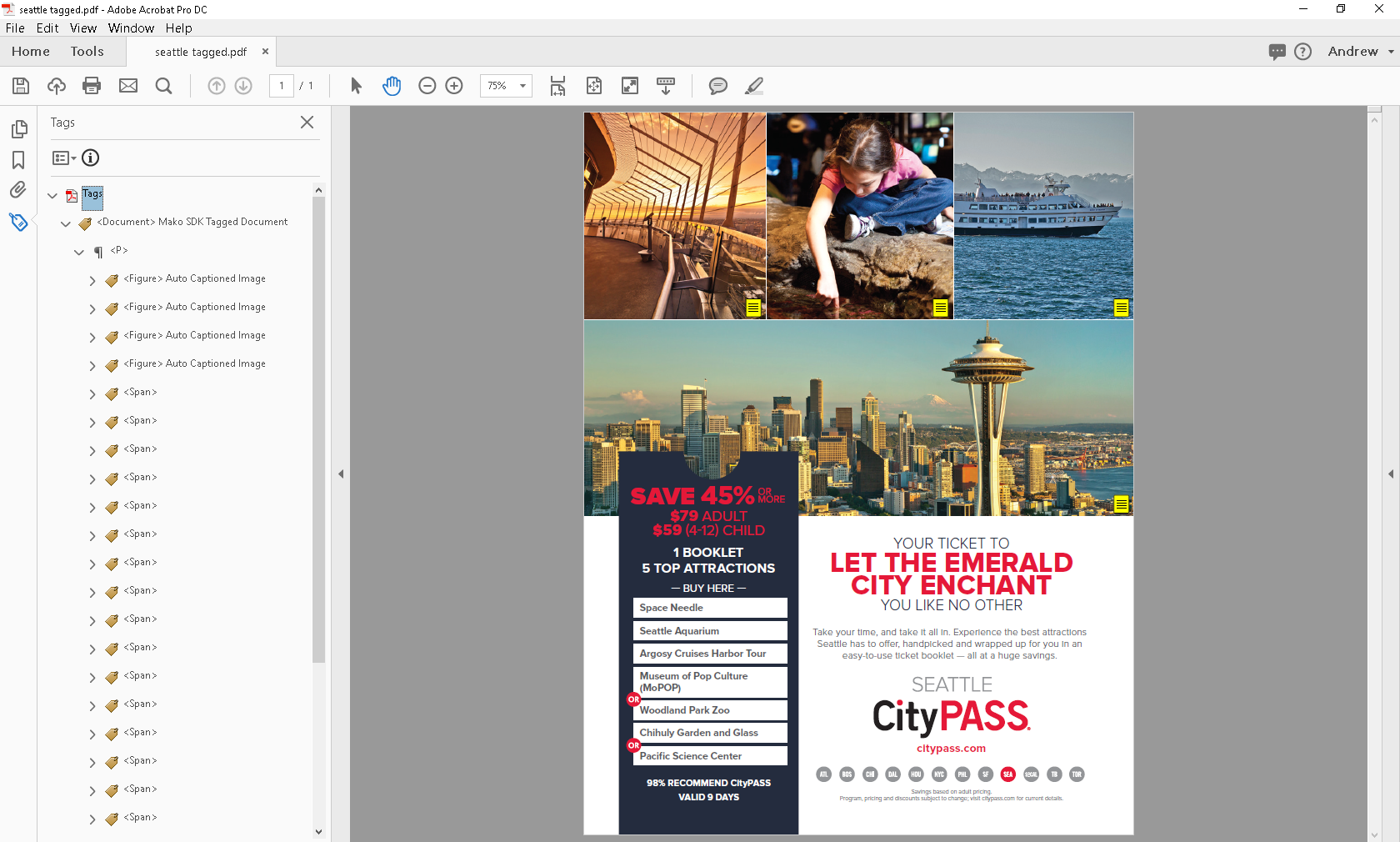
And if we take a look at one of the images, we can see our figure structure now has some alternative text, generated by Microsoft’s Vision API. The alt text will be read by screen readers.
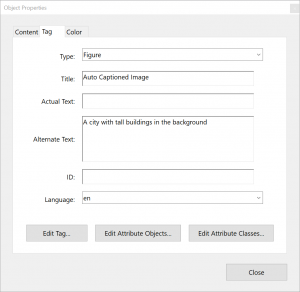
It’s not perfect, but then taking a look at how Adobe handles text selection quite nicely illustrates just how hard it is to get it right. In the image below, I’ve attempted to select the whole of the title text in Acrobat.
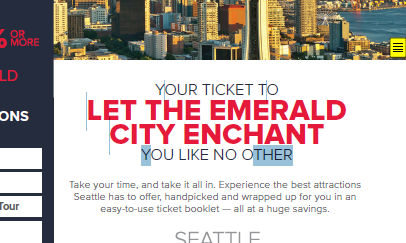
In comparison, our page layout analysis seems to have gotten these particular text runs spot on. But how does it fair with the Jaws screen reader? Let’s see it in action!
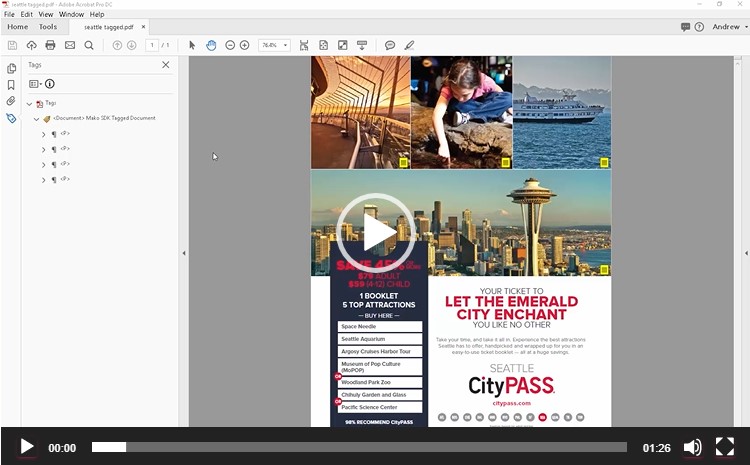
So, it does a pretty good job. The images have captions automatically generated, there is a sense of flow and most of the content reads in the correct order. Not bad.
Printing accessible PDFs
You may be aware that the Mako SDK comes with a sample virtual printer driver that can print to PDF. I want to take this one step further and add our accessibility structure tagging tool to the printer driver. This way, we could print from any application, and the output will be accessible PDF!
In the video below I’ve found an interesting blog post that I want to save and read offline. If I were partially sighted, it may be somewhat problematic as the PDF printer in Windows 10 doesn’t provide structure tagging, meaning that the PDF I create may not work so well with my combination of PDF reader and screen reader. However, if I throw in my Mako-based structure and image tagger, we’ll see if it can help!
Of course, your mileage will vary and the quality of the tagging will depend on the quality and complexity of the source document. The thing is, structural analysis is a hard problem, made harder sometimes by poorly behaving generators, but that’s another topic in itself. Until all PDF files are created perfectly, we’ll do the best we can!
Want to give it a go?
Please do get in touch if you’re interested in having a play with the technology, or just want to chat about it.

Andy Cardy is a Principal Engineer for Global Graphics Software and a Developer Advocate for the Mako SDK.
Find out more about Mako’s features in Andy’s coding demo:
SHARPEN THE SAW – A LIVE CODING DEMO USING MAKO™
In this session Andy uses coding in C++ and C# to show you three complex tasks that you can easily achieve with Mako:
• PDF rendering – visualizing PDF for screen and print (15 mins)
• Using Mako in Cloud-ready frameworks (15 mins)
• Analyzing and editing with the Mako Document Object Model (15 mins)
To be the first to receive our blog posts, news updates and product news why not subscribe to our monthly newsletter? Subscribe here
Very helpful information. Would it be possible to save the tagged documents PDF/UA compliant?
Hi, I believe we expose the tools you need to meet the technical requirements, but I don’t believe it’s one of our officially supported formats (https://documentation.globalgraphics.com/support/mako/mako-core/documentation/topics/output-parameters-and-presets/output-parameters-pdf). We’d always be interested in hearing use cases though, and you can suggest it as a feature using our support portal (https://jira.globalgraphics.com/servicedesk/customer/portal/5/create/36).