
There are two completely different forms of variable data handling in the Harlequin RIP®, and I’m sometimes asked why we’ve duplicated functionality like that. The simple answer is that it’s not duplication; they each address very different use cases.
But those use cases are not, as many people then expect, “white paper workflows” vs imprinting, i.e. whether the whole design including both re-used and single-use elements is printed together vs adding variable data on top of a pre-printed substrate. Both Harlequin VariData™ and the “Dynamic overlays” that we added in Harlequin version 12 can address both of those requirements.
Incidentally, I put “white paper workflows” in quotes because that’s what it’s called in the transactional and direct mail spaces … but very similar approaches are used for variable data printing in other sectors, which may not be printing on anything even vaguely resembling paper!
The two use cases revolve around who has the data, when they have it, whether a job should start printing before all the data is available, and whether there are any requirements to restrict access to the data.
When most people in the transactional, direct mail or graphic arts print sectors think about variable data it tends to be in the form of a fully resolved document representing all of the many variations of one of a collection of pages, combining one or more static ‘backgrounds’ with single-use variable data elements, and maybe some re-used elements from which one is selected for each recipient. In other words, each page in the PDF file is meant to be printed as-is, and will be suitable for a single copy. That whole, fully resolved file is then sent to the press. It may be sent from one division of the printing company to the press room, or even from some other company entirely. The same approach is used for some VDP jobs in labels, folding carton, corrugated, signage and some industrial sectors.
This is the model for which optimized PostScript, and then optimized PDF, PDF/VT (and AFP) were designed. It’s a robust workflow that allows for significant amounts of proofing and process control at multiple stages. And it also allows very rich graphical variability. It’s the workflow for which Harlequin VariData was designed, to maximize the throughput of variable data files through the Digital Front End (DFE) and onto the press.
But in some cases the variable data is not available when the job starts printing. Indeed, the print ‘job’ may run for months in situations such as packaging lines or ID card printing. That can be managed by simply sending a whole series of optimized PDF files, each one representing a few thousand or a couple of million instances of the job to be printed. But in some cases that’s simply not convenient or efficient enough.
In other workflows the data to be printed must be selected based on the item to be printed on, and that’s only known at the very last minute … or second … before the item is printed. A rather extreme example of this is in printing ID cards. In some workflows a chip or magnetic strip is programmed first. When the card is to be printed it’s obviously important that the printed information matches the data on the chip or magnetic strip, so the printing unit reads the data from one of those, uses that to select the data to be printed, and prints it … sometimes all in less than a second. In this case you could use a fully resolved optimized PDF file and select the appropriate page from it based on identifying the next product to be printed on; I know there are companies doing exactly that. But it gets cumbersome when the selection time is very short and the number of items to be printed is very large. And you also need to have all of the data available up-front, so a more dynamic solution is better.
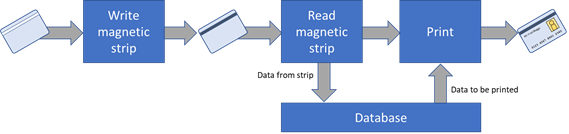
In other cases there is a need to ensure that the data to be printed is held completely securely, which usually leads to a demand that there is never a complete set of that data in a standard file format outside of the DFE for the printer itself. ID cards are an example of this use case as well.

Moving away from very quick or secure responses, we’ve been observing an interesting trend in the labels and packaging market as digital presses are used more widely. Printing the graphics of the design itself and adding the kind of data that’s historically been applied using coding and marking are converging. Information like serial numbers, batch numbers, competition QR Codes, even sell & use by dates are being printed at the same time as the main graphics. Add in the growing demands for traceability, for less of a need for warehousing and for more print on demand of a larger number of different versions, and there can be some real benefits in moving all of the print process quite close to the bottling/filling/labelling lines. But it doesn’t make sense to make a million page PDF file just so you can change the batch number every 42 cartons because that’s what fits on a pallet.
These use cases are why we added Dynamic overlays to Harlequin. Locations on the output where marks should be added are specified, along with the type of mark (text, barcodes and images are the most commonly used). For most marks a data source must be specified; by default we support reading from CSV files or automated counters, but an interface to a database can easily be added for specific integrations. And, of course, formatting information such as font, color, barcode symbology etc must be provided.
The ‘overlay’ in “Dynamic overlays” gives away one of the limitations of this approach, in that the variable data added using it must be on top of all the static data. But we normally recommend that you do that for fully resolved VDP submissions using something like optimized PDF anyway because it makes processing much more efficient; there aren’t that many situations where the desired visual appearance requires variable graphics behind static ones. It’s also much less of a constraint that you’d have with imprinting, where you can only knock objects like white text out of a colored fill in the static background if you are using a white ink!
For what it’s worth, Dynamic overlays also work well for imprinting or for cases where you need to print graphics of middling complexity at high quality but where there are no static graphics at all (existing coding & marking systems can handle simple graphics at low to medium quality very well). In other words, there’s no need to have a background to print the variable data as a foreground over.
So now you know why we’ve doubled up on variable data functionality!
Further reading:
- What’s the best effective photographic image resolution for your variable data print jobs?
- Why does optimization of VDP jobs matter?
To be the first to receive our blog posts, news updates and product news why not subscribe to our monthly newsletter? Subscribe here
Follow us on LinkedIn and Twitter